參考資料:
1. 李弘毅的ML講義
2. [機器學習 ML NOTE] Reinforcement Learning 強化學習(DQN原理)
3. 反向增強學習入門1——基本概念
• 原理說明:自動進行決策,並且可以做連續決策
終於來到了最後一關(?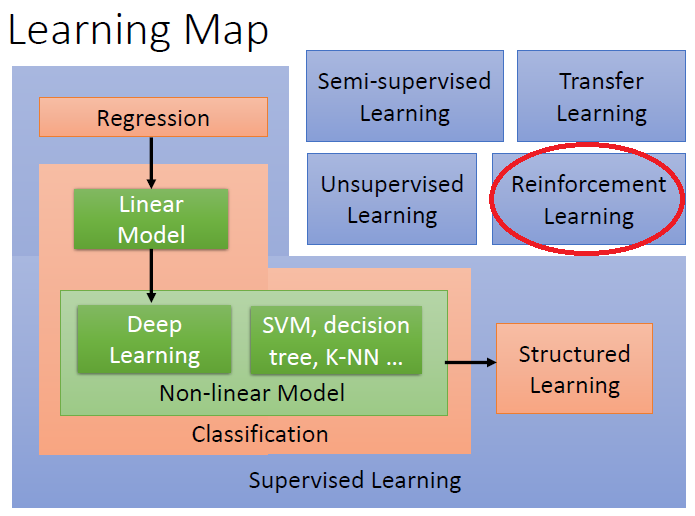
Reinforcement Learning : 從現在的環境來決定行為,是一種互動式的學習過程。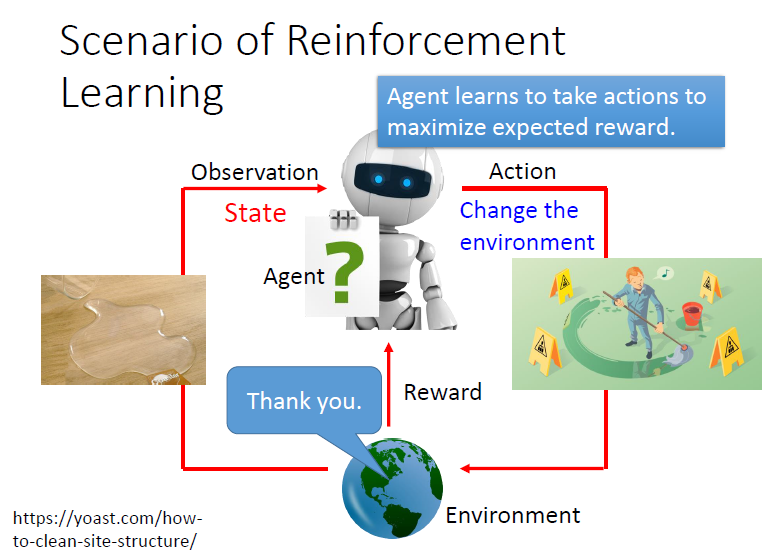
• 四個元素:agent、環境狀態、行動、獎勵
由上圖可知
agent就像大腦,依據當下的state還有enviroment,做出action去改變enviroment時,會得到reward來學習那次的action是不是好的。
因此
強化學習的目的就是找到一個最好的action,可以讓reward最大。
#一連串的action(行動)之後就稱為policy(政策)
• Q-Learning解說
Value function 價值函數: 用來定義目前state跟policy的好與壞,也可以說是"這個狀態對未來reward的期望"
Bellman方程有二個最基本的算法,Policy Iteration 和 Value Iteration
而Q-learning的想法是由Value Iteration所得到的
value iteration利用新得到的reward和原本的Q值來更新現在的Q值
然後Q-learning的更新公式:
一開始的值可能是錯的,但經過一次又一次的疊代,target Q也會越來越精準,所以如果時間夠長,value-function就可以優化為最優的價值函數,這就是Q-learning
• 逆向增強式學習 (Inverse Reinforcement Learning)
強化學習背後的假設是馬爾科夫決策過程 (MDP)。
馬爾可夫決策過程是基於馬爾可夫過程理論的隨機動態系統的決策過程。
基於Reinforcement Learning的概念,逆向強化學習反而是:系統進行探索的過程中,環境不給出獎勵。
WHY? FOR EXAMPLE:導航
導航行為的優劣,只有在最後(例如到達目的地)才會知道
整理成步驟的話:
• 主題解說:訓練電腦玩遊戲、機器人運動控制
Example: Playing Video Game
○ Widely studies:
Gym: https://gym.openai.com/
Universe: https://openai.com/blog/universe/


 iThome鐵人賽
iThome鐵人賽